El coste de oportunidad de lo manual: Automatización vs Tareas manuales
En el escenario competitivo actual, el recurso más valioso de una organización es el tiempo de su talento. Sin embargo, muchas empresas sufren un drenaje invisible: profesionales cualificados dedicando horas a procesos manuales repetitivos, validación de registros y traspaso de información entre plataformas.
Este no es solo un problema de eficiencia operativa; es un problema de coste de oportunidad. Cada hora invertida en una tarea que un algoritmo puede resolver es una hora que se resta a la innovación, al análisis estratégico y al crecimiento del negocio. La automatización no busca sustituir a las personas, sino liberar su potencial para que se enfoquen en tareas donde el criterio humano aporta un valor diferencial.
El desafío de los silos tecnológicos
¿Por qué es tan difícil automatizar? El principal obstáculo suele ser la fragmentación de sistemas. Es habitual que el dato de origen resida en unas infraestructuras, mientras que las herramientas más ágiles para la orquestación lógica o la ejecución final operen en otros sistemas o mediante servicios externos especializados.
Esta «distancia técnica» entre nubes o sistemas suele forzar a las organizaciones a mantener puentes humanos (personas moviendo Excels de un sitio a otro). Romper estos silos requiere una arquitectura que convierta el obstáculo Multi-Cloud en un flujo de datos transparente y seguro.
Como caso de uso para esta arquitectura, presentamos una infraestructura orquestada entre nubes para gestionar flujos de correo electrónico altamente segmentados. Al integrar diversas plataformas, hemos logrado que los criterios de negocio definidos en el origen se ejecuten con una precisión quirúrgica en el destino. Es una solución pensada por y para la flexibilidad, donde cada paso del flujo es personalizable, permitiendo que el dato sea el que dicte la acción final sin necesidad de supervisión manual constante.
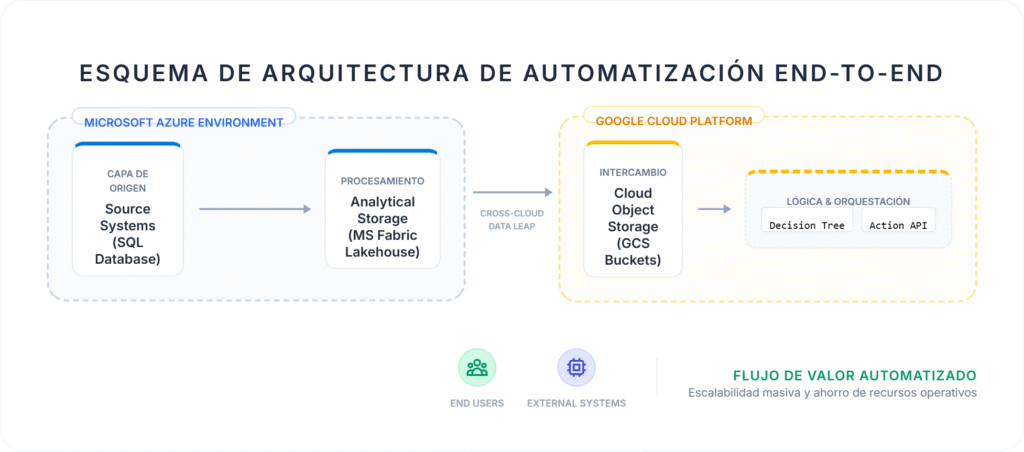
La Solución: Un flujo de valor en cuatro etapas
Para solventar esta brecha, hemos implementado una solución técnica robusta que orquesta el camino desde el dato bruto hasta la acción final:
Fase 1: Ingesta Inteligente (Azure)
Extraemos la información de los sistemas centrales de gestión mediante pipelines automatizados en Microsoft Fabric. Creamos una copia analítica optimizada que permite trabajar con volúmenes masivos de datos sin afectar al rendimiento de los sistemas en vivo.
Fase 2: El Puente Multi-Cloud
Implementamos un motor de procesamiento que realiza el traslado del dato hacia Google Cloud Storage. Lo más relevante: el proceso ocurre íntegramente en memoria, eliminando riesgos de seguridad y latencias innecesarias al evitar archivos físicos intermedios.
Fase 3: Cerebro Lógico de Decisión (GCP)
Una vez el dato aterriza en Google Cloud, un motor programado en Python toma el control. Este componente aplica reglas de negocio complejas (árboles de decisión) para clasificar cada registro y determinar qué acción exacta requiere, asegurando que el proceso sea inteligente y no solo una mera transferencia de datos.
Fase 4: Ejecución mediante API
El sistema se comunica con plataformas externas para disparar las acciones finales. El dato ya procesado se convierte en un impacto real y personalizado para el destinatario final, de forma masiva y sin errores.
Fase 1: Ingesta Inteligente
El flujo comienza en el núcleo de la infraestructura de Microsoft. En lugar de forzar a los sistemas transaccionales a procesar reglas de negocio complejas, utilizamos Fabric Pipelines para realizar una extracción limpia y asíncrona.
El dato se deposita en un Lakehouse bajo formato Parquet (Delta en la versión Microsoft). Esta decisión es estratégica: el formato Parquet nos permite reducir el peso de los archivos drásticamente mediante compresiones altamente optimizadas, facilitando que procesos posteriores lean millones de filas en milisegundos sin latencia de disco y desacoplando la capa analítica de la capa de producción del dato crudo.
Más información sobre como trabaja Microsoft las tablas Delta
Fase 2: El Salto Seguro (The Memory Handshake)
El mayor desafío de una arquitectura Multi-Cloud es el trasvase de información sin comprometer la seguridad ni la integridad del dato. Para conectar Azure con Google Cloud, implementamos una capa de computación distribuida que realiza un traspaso íntegramente en memoria.
A diferencia de las integraciones tradicionales que descargan archivos en carpetas locales —creando brechas de seguridad y aumentando el tiempo de proceso—, esta arquitectura lee el dato en el Lakehouse y lo «inyecta» directamente en un bucket de Google Cloud Storage (GCS) a través de flujos cifrados y Spark. La autenticación se gestiona mediante el servicio de identidades técnicas aisladas de Google (IAM), asegurando que solo los procesos autorizados puedan realizar este «apretón de manos» entre nubes.
Fase 3: Inteligencia Operativa y Resiliencia
Una vez el dato reside en el ecosistema de Google, un orquestador (Airflow) activa el componente más crítico: el motor lógico. No se trata simplemente de una transferencia; el sistema debe «entender» qué hacer con cada dato.
Utilizando un Árbol de Decisiones dinámico, el sistema analiza cada registro para determinar su prioridad, su canal de salida y el momento óptimo de ejecución. Hemos dotado a este cerebro de Idempotencia: una propiedad de ingeniería que garantiza que, si ocurre un fallo durante el proceso, el sistema sepa exactamente dónde se detuvo para reanudarlo sin duplicar acciones ni perder información, protegiendo la fiabilidad total del flujo.
El objetivo de esta fase no es solo filtrar datos, sino enriquecerlos. El sistema analiza cada registro individualmente y genera como salida una serie de «Jobs» (archivos de trabajo estructurados). Estos «jobs» son paquetes de información que recogen todos los metadatos necesarios para que la comunicación sea perfecta y permite que el motor lógico sea agnóstico al proveedor: hoy inyectamos estos metadatos en una API de mailing, pero la arquitectura está preparada para disparar notificaciones push, SMS o actualizaciones en un CRM simultáneamente.
Fase 4: Ejecución Masiva vía API
La etapa final convierte esos «Jobs» en impacto real. En lugar de procesar la lógica mientras se realiza el envío, el sistema simplemente consume los metadatos preparados en la fase anterior
Este diseño permite una escalabilidad horizontal total. Ya sea que necesitemos accionar 50 registros o 50.000, la infraestructura responde de forma elástica, disparando miles de procesos en paralelo con una monitorización detallada de cada respuesta recibida. El círculo se cierra cuando el dato analítico estático se convierte en una acción operativa finalizada con éxito.
Siguientes Pasos: IA y Personalización Extrema
Esta arquitectura es solo el cimiento. La verdadera evolución reside en la integración de algoritmos de Inteligencia Artificial en el motor de decisiones.
En una segunda iteración, la IA permitirá pasar de reglas de negocio estáticas a una personalización dinámica total. Podremos predecir el mejor momento para ejecutar cada acción según el comportamiento histórico y utilizar modelos de lenguaje (LLM) para generar respuestas o contenidos únicos para cada registro en tiempo real. Estamos construyendo la base para que el dato no solo fluya, sino que «aprenda» a ser más efectivo en cada ejecución.