Del dato analítico a la acción operativa.
Sin que nadie lo supervise.
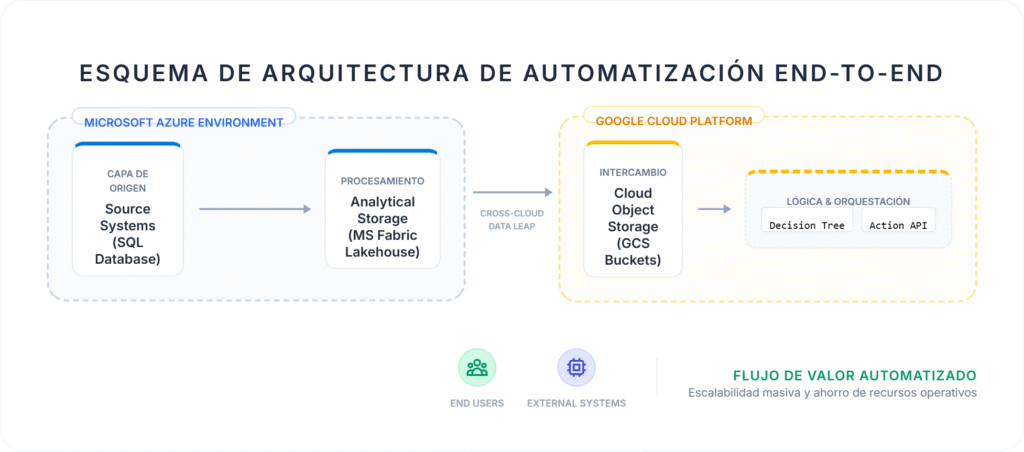
Arquitectura end-to-end que conecta Azure y GCP para convertir datos en acciones automatizadas, eliminando la dependencia humana en cada paso del flujo.
4 fases
Pipeline completo
0h
Supervisión manual
2 nubes
Azure + GCP
∞
Escalabilidad horizontal
En el escenario competitivo actual, el recurso más valioso de una organización es el tiempo de su talento. Sin embargo, muchas empresas sufren un drenaje invisible: profesionales cualificados dedicando horas a procesos manuales repetitivos, validación de registros y traspaso de información entre plataformas.
Este no es solo un problema de eficiencia operativa; es un problema de coste de oportunidad. Cada hora invertida en una tarea que un algoritmo puede resolver es una hora que se resta a la innovación, al análisis estratégico y al crecimiento del negocio.
El principal obstáculo suele ser la fragmentación de sistemas. El dato de origen reside en unas infraestructuras mientras que las herramientas de orquestación y ejecución operan en otras. Esta distancia técnica entre nubes fuerza a las organizaciones a mantener puentes humanos. Esta arquitectura los elimina.
Ingesta inteligente
Extracción limpia desde sistemas centrales mediante Microsoft Fabric. Datos en formato Parquet en el Lakehouse, desacoplando la capa analítica de producción.
El puente seguro
Trasvase íntegramente en memoria hacia Google Cloud Storage. Sin archivos físicos intermedios, sin brechas de seguridad, con autenticación IAM aislada.
Cerebro lógico de decisión
Motor Python con árboles de decisión dinámicos. Clasifica cada registro, genera Jobs estructurados y garantiza idempotencia ante fallos del sistema.
Ejecución masiva vía API
Los Jobs se convierten en impacto real. Escalabilidad horizontal total: 50 registros o 50.000, la infraestructura responde de forma elástica y paralela.
Ingesta inteligente · Azure
El flujo comienza en el núcleo de la infraestructura de Microsoft. En lugar de forzar a los sistemas transaccionales a procesar reglas de negocio complejas, utilizamos Fabric Pipelines para realizar una extracción limpia y asíncrona.
El dato se deposita en un Lakehouse bajo formato Parquet. Esta decisión es estratégica: permite reducir el peso de los archivos mediante compresiones altamente optimizadas, facilitando que procesos posteriores lean millones de filas en milisegundos sin latencia de disco.
El formato Delta desacopla completamente la capa analítica de la capa de producción del dato crudo. Los sistemas transaccionales no sufren ningún impacto de rendimiento durante el proceso de extracción.
El puente seguro · Azure → GCP
El mayor desafío de una arquitectura Multi-Cloud es el trasvase de información sin comprometer la seguridad ni la integridad del dato. Para conectar Azure con Google Cloud, implementamos una capa de computación distribuida que realiza un traspaso íntegramente en memoria.
A diferencia de las integraciones tradicionales que descargan archivos en carpetas locales —creando brechas de seguridad y aumentando el tiempo de proceso—, esta arquitectura lee el dato en el Lakehouse y lo inyecta directamente en un bucket de Google Cloud Storage a través de flujos cifrados con Spark.
La autenticación se gestiona mediante identidades técnicas aisladas de Google (IAM). Solo los procesos autorizados pueden realizar este "apretón de manos" entre nubes. Ningún archivo toca disco en ningún momento del proceso.
Cerebro lógico de decisión · GCP
Una vez el dato reside en el ecosistema de Google, un orquestador Airflow activa el componente más crítico: el motor lógico. No se trata de una transferencia; el sistema debe entender qué hacer con cada dato.
Utilizando un árbol de decisiones dinámico, el sistema analiza cada registro para determinar su prioridad, su canal de salida y el momento óptimo de ejecución. Este componente genera como salida una serie de Jobs: paquetes estructurados con todos los metadatos necesarios para que la ejecución final sea perfecta.
Hemos dotado al sistema de idempotencia: si ocurre un fallo durante el proceso, el sistema sabe exactamente dónde se detuvo para reanudarlo sin duplicar acciones ni perder información.
El motor lógico es agnóstico al proveedor. Hoy inyecta metadatos en una API de mailing, pero la arquitectura está preparada para disparar notificaciones push, SMS o actualizaciones en un CRM simultáneamente.
Ejecución masiva vía API · GCP
La etapa final convierte los Jobs en impacto real. En lugar de procesar la lógica mientras se realiza el envío, el sistema simplemente consume los metadatos preparados en la fase anterior.
Este diseño permite una escalabilidad horizontal total. Ya sea que necesitemos accionar 50 registros o 50.000, la infraestructura responde de forma elástica, disparando miles de procesos en paralelo con una monitorización detallada de cada respuesta recibida.
El círculo se cierra cuando el dato analítico estático se convierte en una acción operativa finalizada con éxito. Sin que nadie haya pulsado un botón.
¿Te suena este problema?
¿Tienes datos en distintos sistemas
que no se hablan entre sí?
Eso es exactamente lo que resuelve esta arquitectura. Hablamos 30 minutos y vemos si tiene sentido aplicarla a tu caso.