La detección de anomalías con visión por computador permite identificar defectos en producto antes de que lleguen al cliente, sin necesidad de imágenes etiquetadas de defectos para entrenar el modelo. Este artículo construye el sistema completo desde cero, con código ejecutable y resultados reales.
Artículo de Fundamentos. Dataset: MVTec AD — Hazelnut. Stack: PyTorch, scikit-learn. Todo el código es ejecutable. Los resultados mostrados son reales, generados sobre el dataset completo.
El problema: calidad que depende de quien mira
Una empresa de frutos secos procesa toneladas de avellanas diariamente. Al final de la línea de producción, un inspector visual evalúa el producto: grietas, cortes, agujeros, manchas. En la primera hora del turno, el sistema funciona. En la octava, el inspector ha visto cincuenta mil avellanas y su capacidad de detección ha caído. El reporte de rechazos llega al día siguiente. Para entonces el lote está empaquetado.
El problema no es la persona. Es que el sistema de control de calidad depende de un recurso que se fatiga, que no es consistente entre turnos y que genera el dato cuando la decisión ya es tarde. El reporte es, una vez más, un retrovisor: el mismo problema que hace que la mayoría de empresas solo usen sus datos para explicar lo que ya ocurrió.
El coste invisible
Una avellana defectuosa que supera la inspección no solo genera una devolución. Genera un proceso de trazabilidad, un potencial recall de lote, y un impacto en la confianza del cliente que no aparece en ningún reporte de producción. El dato llega siempre después del daño.
La solución: una cámara que no se fatiga
La propuesta es instalar una cámara sobre la línea de producción conectada a un modelo de visión por computador que evalúa cada avellana en tiempo real. Cuando el score de anomalía supera un umbral, el sistema activa el rechazo automático antes de que el producto llegue al empaquetado.
El problema técnico inmediato es el que convierte esto en un reto real: no tenemos imágenes etiquetadas de defectos para entrenar. En producción, los defectos son raros por definición. Si el sistema funciona bien, hay muy pocas avellanas defectuosas. Y no podemos esperar a acumular miles de defectos etiquetados antes de poder desplegar el modelo. La solución clásica de clasificación supervisada no aplica aquí.
La intuición
Un inspector experimentado que lleva años viendo avellanas perfectas detecta al instante algo que no encaja, aunque nunca haya visto ese defecto exacto antes. No necesita haber visto el defecto para saber que algo está mal: sabe perfectamente cómo es lo correcto, y eso es suficiente. El autoencoder funciona exactamente igual.
El algoritmo y el pipeline
Un autoencoder convolucional es una red neuronal que aprende a comprimir una imagen en una representación compacta y luego reconstruirla. Entrenado exclusivamente sobre imágenes de avellanas correctas, el modelo aprende qué es una avellana normal. Cuando en inferencia recibe una avellana defectuosa, no puede reconstruirla bien: el error de reconstrucción es alto precisamente en la zona del defecto. Ese error es la señal de anomalía.
Arquitectura del autoencoder convolucional. El error entre input y output es la señal de anomalía: alto en zonas defectuosas, bajo en producto correcto.
El dataset que usamos es MVTec AD — categoría hazelnut, el benchmark estándar de detección de anomalías visuales industriales. Contiene 391 imágenes de entrenamiento de avellanas correctas y 110 imágenes de test distribuidas entre avellanas buenas y cuatro tipos de defecto: grieta (crack), corte (cut), agujero (hole) y mancha (print). Cada defecto tiene anotación pixel-precisa para evaluación.
El dataset y el preprocesamiento
Lo primero es entender con qué trabajamos. El dataset tiene una estructura limpia que separa claramente el split de entrenamiento — solo producto correcto — del split de test, que incluye tanto avellanas buenas como las cuatro categorías de defecto.
train_good = DATA_ROOT / "train" / "good"
test_dirs = {d.name: d for d in (DATA_ROOT / "test").iterdir() if d.is_dir()}
print(f"Imágenes de entrenamiento (good): {len(list(train_good.glob('*.png')))}")
print("\nImágenes de test por categoría:")
for cat, path in sorted(test_dirs.items()):
n = len(list(path.glob('*.png')))
print(f" {cat:10s}: {n} imágenes")
Las imágenes originales son de alta resolución (~1024×1024px). Las redimensionamos a 128×128 para acelerar el entrenamiento sin perder la información necesaria para detectar los defectos. La normalización lleva los valores de pixel de [0,255] a [-1,1], que es la escala que espera la función de activación Tanh del decoder.
# Entrenamiento: ligera augmentación para mejorar generalización
train_transform = transforms.Compose([
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(degrees=10),
transforms.ColorJitter(brightness=0.1, contrast=0.1),
transforms.ToTensor(), # [0,255] → [0,1]
transforms.Normalize([0.5]*3, [0.5]*3), # [0,1] → [-1,1]
])
# Test: sin augmentación, solo resize y normalización
test_transform = transforms.Compose([
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.ToTensor(),
transforms.Normalize([0.5]*3, [0.5]*3),
])
# Train: SOLO imágenes good — el modelo nunca ve un defecto durante el entrenamiento
train_samples = [(p, 0) for p in sorted(train_good.glob('*.png'))]
# Test: good (label=0) + todas las categorías de defecto (label=1)
test_samples = [(p, 0) for p in sorted((DATA_ROOT / "test" / "good").glob('*.png'))]
for cat in defect_categories:
test_samples += [(p, 1) for p in sorted((DATA_ROOT / "test" / cat).glob('*.png'))]
La arquitectura del autoencoder
El encoder reduce progresivamente la resolución espacial de la imagen a través de cuatro bloques convolucionales con MaxPool, comprimiendo la representación de 3×128×128 hasta un bottleneck de 512×8×8. Cada bloque aplica BatchNorm para estabilizar el entrenamiento y LeakyReLU como activación para no perder gradiente en valores negativos. El decoder es simétrico: reconstruye la resolución original con ConvTranspose2d hasta devolver una imagen de 3×128×128 en escala [-1,1] gracias a Tanh.
class ConvAutoencoder(nn.Module):
"""
Autoencoder convolucional simétrico.
Input: (B, 3, 128, 128)
Latent: (B, 512, 8, 8) → 512 mapas de características de 8x8
Output: (B, 3, 128, 128)
"""
def __init__(self):
super().__init__()
# ── Encoder: compresión progresiva ────────────────────────────────────
self.encoder = nn.Sequential(
# 3×128×128 → 32×64×64
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32), nn.LeakyReLU(0.2, inplace=True),
nn.MaxPool2d(2, 2),
# 32×64×64 → 64×32×32
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64), nn.LeakyReLU(0.2, inplace=True),
nn.MaxPool2d(2, 2),
# 64×32×32 → 128×16×16
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128), nn.LeakyReLU(0.2, inplace=True),
nn.MaxPool2d(2, 2),
# 128×16×16 → 256×8×8
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256), nn.LeakyReLU(0.2, inplace=True),
nn.MaxPool2d(2, 2),
# 256×8×8 → 512×8×8 (bottleneck, sin reducción espacial)
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512), nn.LeakyReLU(0.2, inplace=True),
)
# ── Decoder: reconstrucción progresiva ────────────────────────────────
self.decoder = nn.Sequential(
nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2), # ×2
nn.BatchNorm2d(256), nn.ReLU(inplace=True),
nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2), # ×2
nn.BatchNorm2d(128), nn.ReLU(inplace=True),
nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2), # ×2
nn.BatchNorm2d(64), nn.ReLU(inplace=True),
nn.ConvTranspose2d(64, 32, kernel_size=2, stride=2), # ×2
nn.BatchNorm2d(32), nn.ReLU(inplace=True),
# Capa final: 3 canales + Tanh para escala [-1,1]
nn.Conv2d(32, 3, kernel_size=3, padding=1),
nn.Tanh(),
)
def forward(self, x):
return self.decoder(self.encoder(x))Por qué 2,2M de parámetros es razonable
Un modelo de detección supervisado preentrenado (ResNet50, EfficientNet) tiene entre 25M y 80M de parámetros. El autoencoder con 2,2M parámetros es significativamente más ligero, más rápido en inferencia y no requiere GPU para producción. Para una línea de producción con cámara industrial, eso es una ventaja operativa, no una limitación.
Entrenamiento
La función de pérdida es MSE (Mean Squared Error): penaliza la diferencia pixel a pixel entre la imagen original y la reconstruida. El optimizador es Adam con weight decay para regularización. Añadimos un scheduler que reduce el learning rate cuando la pérdida se estanca, lo que permite que el modelo siga mejorando en las últimas épocas sin divergir.
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-5)
# Reduce LR a la mitad si la pérdida no mejora en 5 épocas consecutivas
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode='min', factor=0.5, patience=5
)
for epoch in range(1, EPOCHS + 1):
model.train()
epoch_loss = 0.0
for imgs, _, _ in train_loader:
imgs = imgs.to(DEVICE)
optimizer.zero_grad()
reconstructed = model(imgs)
loss = criterion(reconstructed, imgs) # reconstrucción vs original
loss.backward()
optimizer.step()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(train_loader)
scheduler.step(avg_loss)
# Guardamos solo el mejor modelo
if avg_loss < best_loss:
best_loss = avg_loss
torch.save(model.state_dict(), "best_autoencoder.pth")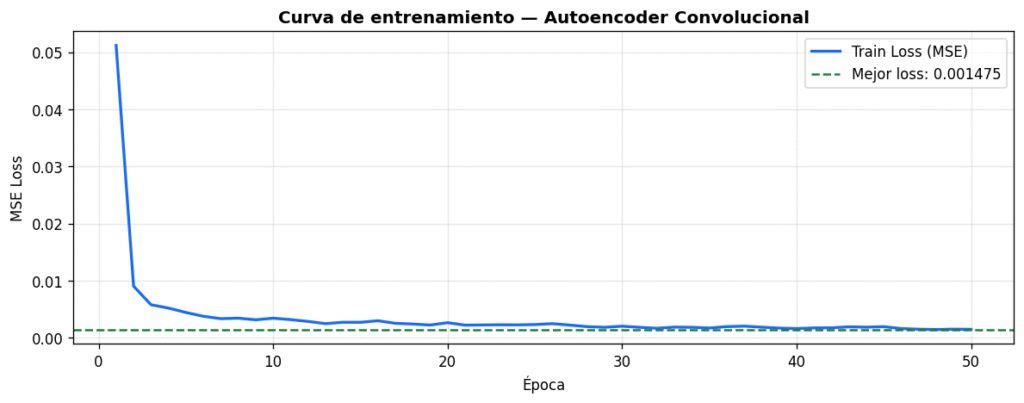
Qué significa este número
Un MSE de 0.001475 sobre imágenes normalizadas en [-1,1] significa que el modelo reconstruye cada pixel con un error medio de aproximadamente 0.038 unidades. Sobre una avellana correcta, eso es ruido de fondo. Sobre una zona defectuosa, el error se dispara localemente, y esa diferencia es exactamente la señal que buscamos.
El mapa de anomalía
Una vez entrenado el modelo, la inferencia calcula el error cuadrático pixel a pixel entre la imagen original y su reconstrucción, promediado sobre los tres canales RGB. El resultado es un mapa de 128×128 valores donde cada pixel representa cuánto le costó al modelo reconstruir esa zona. Las zonas defectuosas producen errores sistemáticamente más altos.
def compute_anomaly_score(img_tensor, model, device):
"""
Recibe un tensor (3, H, W) normalizado en [-1, 1].
Devuelve el mapa de error normalizado y el score global.
"""
with torch.no_grad():
img_tensor = img_tensor.unsqueeze(0).to(device) # (1,3,H,W)
reconstructed = model(img_tensor)
# Error cuadrático pixel a pixel, promediado sobre canales RGB
error_map = ((img_tensor - reconstructed) ** 2).mean(dim=1) # (1,H,W)
anomaly_map = error_map.squeeze().cpu().numpy() # (H,W)
# Normalizamos a [0,1] para visualización
a_min, a_max = anomaly_map.min(), anomaly_map.max()
anomaly_map_norm = (anomaly_map - a_min) / (a_max - a_min + 1e-8)
# Score global: MSE medio de la imagen completa
score = float(anomaly_map.mean())
return reconstructed.squeeze().cpu(), anomaly_map_norm, score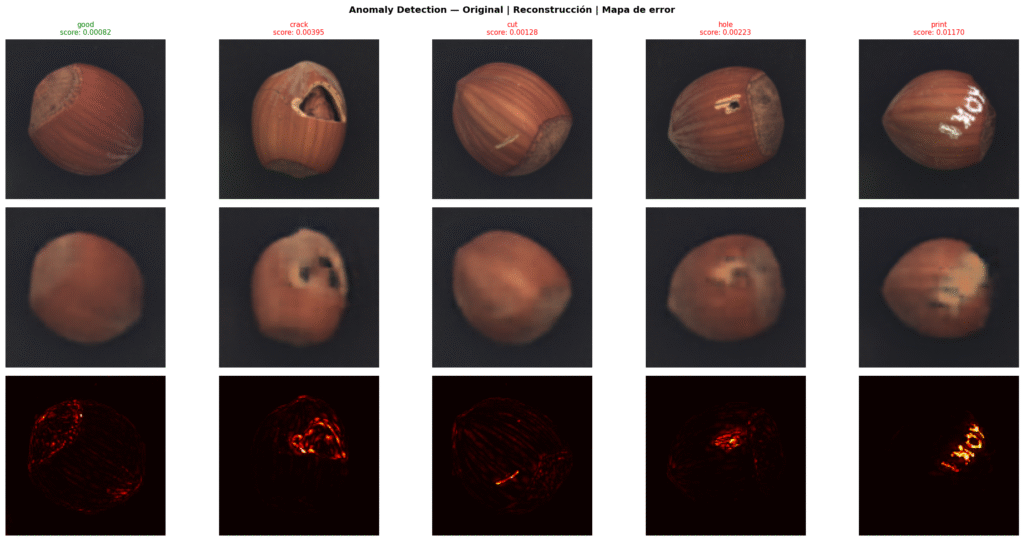
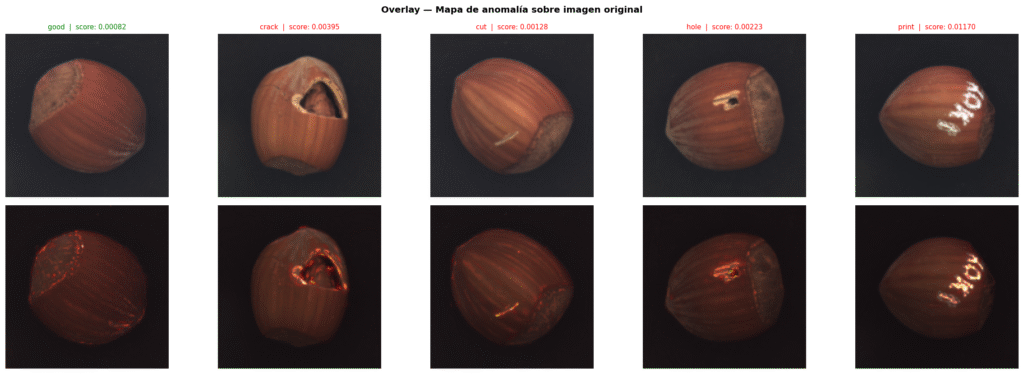
Lo que hace poderoso el overlay no es solo que detecte la anomalía, sino que la localiza. En un sistema de producción, eso permite no solo rechazar el producto defectuoso sino registrar qué tipo de defecto aparece con más frecuencia y en qué zona de la línea. Esa información es el dato que el sistema reactivo nunca podía producir.
Evaluación: AUROC y distribución de scores
Calculamos el AUROC (Area Under the ROC Curve) sobre el test set completo: 110 imágenes, 40 normales y 70 defectuosas. El AUROC mide qué tan bien el score de anomalía separa las dos clases independientemente del umbral elegido. Un valor de 1.0 es separación perfecta; 0.5 es aleatorio.
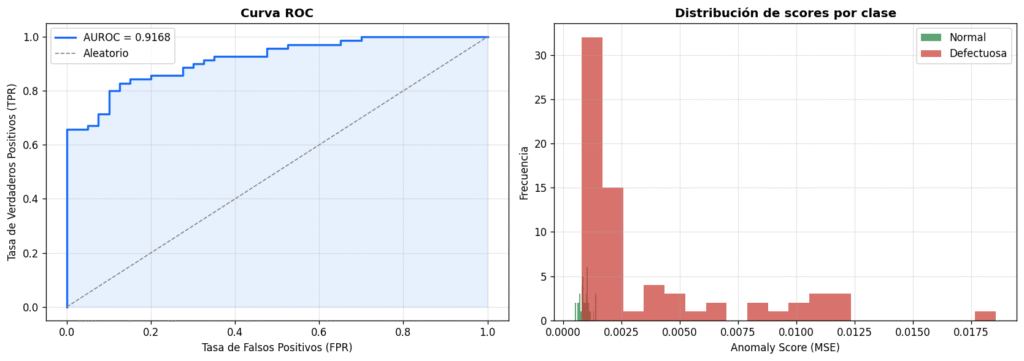
Por qué 0.9168 es un resultado sólido
Este AUROC se obtiene con un autoencoder simple, entrenado en CPU en menos de una hora, sobre 391 imágenes de entrenamiento, sin haber visto nunca un defecto. Métodos más sofisticados como PatchCore o WinCLIP alcanzan AUROC de 0.98+ en el mismo dataset, pero requieren preentrenamiento en ImageNet o modelos de 100M+ parámetros. El autoencoder es el punto de partida correcto para validar que el sistema funciona antes de escalar la complejidad.
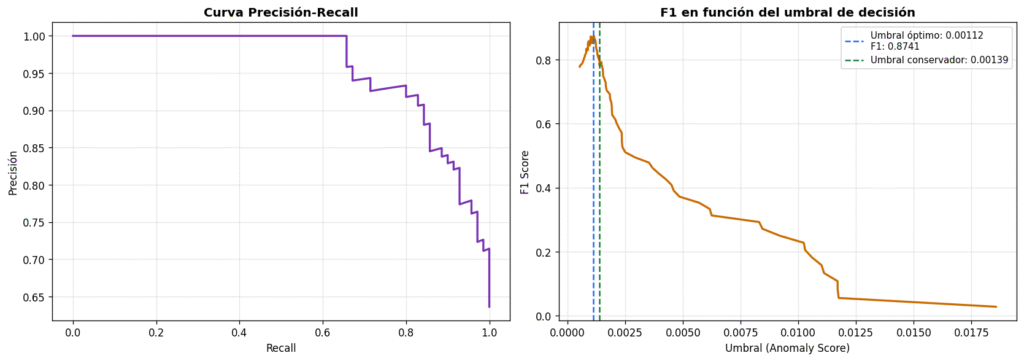
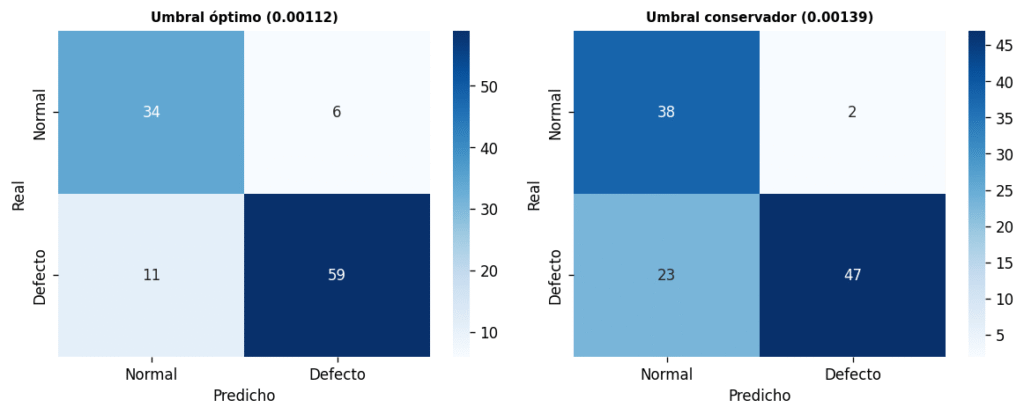
El umbral de decisión: el parámetro de negocio
El umbral es donde la matemática se convierte en decisión de negocio. Define a partir de qué score una avellana se rechaza. No existe un umbral universalmente correcto: depende del coste relativo de cada tipo de error. Un falso negativo —defecto que pasa como bueno— tiene el coste de una devolución o un recall. Un falso positivo —producto bueno rechazado— tiene el coste de la merma.
Resultados por tipo de defecto
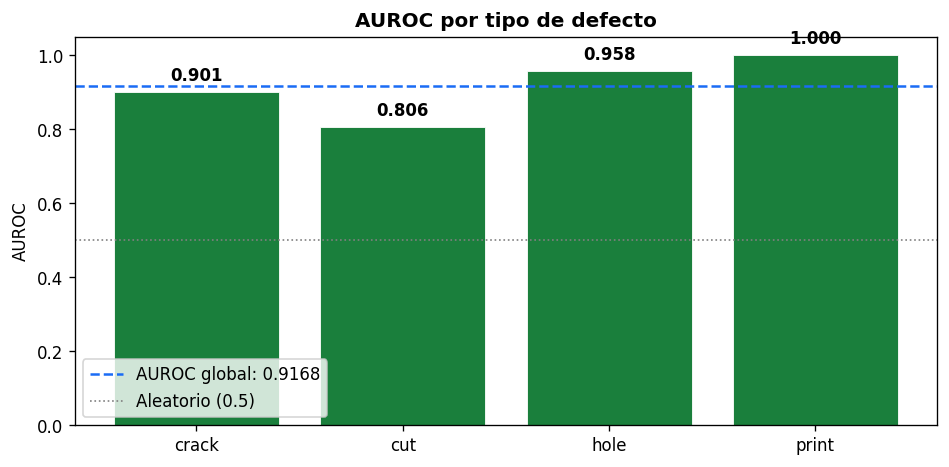
La variabilidad entre defectos tiene una explicación intuitiva. Una mancha (print) es visualmente muy diferente de la textura uniforme de una avellana normal: el modelo la detecta siempre. Un corte fino (cut) puede parecerse a una variación natural de la superficie: el modelo falla en los casos más sutiles. En producción real, eso informa dónde poner la cámara, con qué resolución y con qué iluminación para maximizar la visibilidad del defecto específico que más importa controlar.
Resultados y puesta en producción
El sistema se integra en la línea conectando la salida del modelo a un actuador de rechazo. El flujo en producción es simple: la cámara captura la imagen, el modelo calcula el score en menos de 50ms, si el score supera el umbral configurado se activa el rechazo automático y se registra el evento con timestamp, imagen y score para trazabilidad.
AUROC global
0.9168
Separación entre producto normal y defectuoso sobre 110 imágenes de test
F1 Score en umbral óptimo
0.874
Balance precisión-recall con umbral 0.00112
Defectos detectados
59 / 70
84% de los defectos identificados correctamente
Parámetros del modelo
2,2M
Inferencia <50ms en CPU. No requiere GPU en producción
Print detection
1.000
AUROC perfecto en detección de manchas superficiales
Imágenes de entrenamiento
391
Solo producto correcto. Cero imágenes de defectos necesarias para entrenar
Lo que cambia con este sistema no es solo la tasa de detección. Es la naturaleza del dato que produce. El sistema reactivo generaba un reporte de rechazos al día siguiente. Este sistema genera un evento por cada avellana inspeccionada: timestamp, score, categoría predicha, imagen. Ese historial permite detectar tendencias de degradación en la línea antes de que el problema sea visible a simple vista. De retrovisor a sensor proactivo.
Framework de decisión: cuándo usar un autoencoder
Framework — Autoencoder convolucional para detección de anomalías
¿Tienes imágenes etiquetadas de defectos?
No → El autoencoder es tu punto de partida. Entrenas solo con producto correcto y empiezas a generar valor desde el primer día.
¿Los defectos son visualmente muy distintos entre sí?
Sí → El autoencoder lo detecta bien. Si los defectos son sutiles y similares a variaciones normales (como el cut en este caso), considera PatchCore o métodos con preentrenamiento.
¿Necesitas inferencia en tiempo real sin GPU?
Sí → El autoencoder con 2,2M parámetros infiere en <50ms en CPU. Apto para líneas de producción con hardware industrial estándar.
¿Necesitas localización del defecto además de detección?
Sí → El mapa de anomalía lo proporciona de forma nativa. No necesitas anotaciones adicionales ni un modelo de segmentación separado.
¿AUROC de 0.91 es suficiente para tu caso de uso?
No → Escala a PatchCore (AUROC ~0.98 en MVTec) o WinCLIP con backbone CLIP. Si además tienes imágenes etiquetadas de defectos, la detección supervisada abre otro nivel: comparativa YOLO vs Faster R-CNN →
El autoencoder convolucional no es la solución más sofisticada para detección de anomalías visuales. Es la solución más honesta: entrena con lo que tienes, produce resultados interpretables y genera el dato que el sistema reactivo nunca producía. La pregunta que me gustaría que te llevaras es esta: ¿qué procesos de tu operación dependen hoy de un inspector humano que genera el reporte cuando el producto ya ha pasado, y qué costaría poner una cámara y un modelo que lo vea en tiempo real?
¿Te ha resultado útil?
¿Tienes un problema que
los datos podrían resolver?
Sin formularios largos. Una conversación de 30 minutos para ver si tiene sentido.
Hablamos