
Problema: El «Abismo del MLOps»
La mayoría de los proyectos de forecasting mueren de la misma forma: Un éxito rotundo en el laboratorio que se convierte en el mejor de los casos, en unos resultados operativos en la vida real muy por debajo de las expectativas generadas.
Si has trabajado con equipos tecnológicos seguro que has vivido algo muy parecido: El equipo de proyecto prepara una solución excelente (seguramente con IA integrada) con errores bajísimos, graficas de validación que son una obra de arte y una presentación que dejan a los stakeholders con la boca abierta… hasta que llega el lunes por la mañana y se intenta poner en producción.
En el mejor de los casos, ese modelo dependerá de un experto que supervise de forma recurrente las métricas y vaya ajustando de forma manual en función de la ingesta de datos; En el peor de los casos, el pipeline nunca llegará a ser consistente y morirá entre numerosos intentos de hacerlo funcionar de forma autónoma tras una abrumadora cantidad de horas dedicadas. Ahí es donde aparece «El abismo del MLOps»
El abismo es ese vacío que existe entre tener un modelo que funciona en el ordenador de un analista y tener un sistema que entrega predicciones precisas, automáticas y resilientes al equipo de ventas cada vez que el mercado se mueve.
Stack y Servicios
Llevar un modelo de forecasting del entorno de experimentación (Notebook) a la acción operativa real requiere una arquitectura que garantice que el dato fluya sin fricciones y, sobre todo, sin intervención humana. Para este caso de uso, hemos diseñado una solución 100% Serverless en Google Cloud, priorizando la escalabilidad automática y el pago por uso «cost-effective».
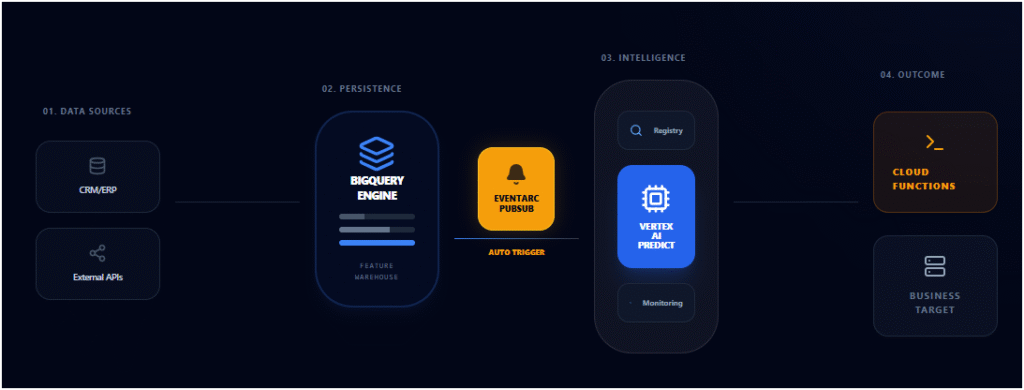
La clave de este stack no es solo procesar datos, sino orquestar el ciclo de vida completo del modelo bajo una filosofía MLOps:
- Ingesta y Eventos: Utilizamos la naturaleza reactiva de la nube para que cada nuevo dato active el flujo de inferencia de forma inmediata, eliminando las esperas de procesos por lotes (batch) tradicionales.
- Abstracción de Infraestructura: Al apoyarnos en servicios gestionados, garantizamos que la lógica de negocio (Python + Modelos) sea independiente del servidor, permitiendo una resiliencia total y una latencia mínima en la respuesta
- Gobernanza y Monitorización: Centralizamos la inteligencia en un entorno donde el rendimiento del modelo se audita en tiempo real, asegurando que las decisiones automatizadas mantengan la precisión algorítmica necesaria para el ROI del negocio.
BigQuery
El corazón del dato. No solo almacena, sino que actúa como el motor de pre-procesamiento a escala petabyte.
Eventarc
El sistema nervioso. Captura eventos en tiempo real (como la entrada de una nueva venta) para disparar la predicción.
Vertex AI Pipeline
El cerebro. Donde reside el modelo entrenado, gestionando versiones y sirviendo las predicciones a través de endpoints escalables.
Cloud Functions
El músculo ejecutor. Microservicios en Python que ejecutan la lógica de inferencia e idempotencia de forma ligera y rápida.
Solución End-to-End
El corazón del dato
Como en toda receta de comida, lo primero con lo que debemos contar es con los ingredientes adecuados. La materia prima es fundamental y en muchas ocasiones queda infravalorada, por lo que para nuestra receta le daremos la importancia que merece.
El primer paso siempre será recolectar los datos necesarios. Aquí nos encontraremos una infinidad de fuentes distintas: desde dato crudo producido directamente en entornos de producción como CRM o ERP que podemos absorber vía API, hasta automatizaciones que nos dejan ficheros eficientes en formato .parquet listos para ser consumidos. Este dato necesita almacenarse en entornos seguros que garanticen su persistencia e integridad — y es aquí donde confiamos en BigQuery.

BigQuery actúa como la base operativa de todo el pipeline. No solo almacena: desacopla el coste de almacenamiento del coste analítico, escala automáticamente y permite analizar millones de registros con latencia mínima. Cada nueva venta registrada en el CRM aterriza aquí, en una tabla dedicada que actúa como punto de entrada del sistema.
El sistema nervioso: Eventarc
Aquí es donde el pipeline cobra vida propia y pasamos de una solución aislada a todo un sistema de gestión integrado.

Configuramos un trigger en Eventarc que escucha inserciones en tiempo real sobre la tabla de ventas de BigQuery. Cada vez que una nueva fila entra en la tabla — una venta registrada, una actualización de pedido — Eventarc captura ese evento y lo propaga al siguiente eslabón del pipeline de forma inmediata, sin esperas, sin procesos batch nocturnos, sin que nadie tenga que pulsar un botón.
Este es el punto exacto donde rompemos con el modelo tradicional. En lugar de ejecutar predicciones una vez al día sobre datos de ayer, el sistema reacciona al dato en el momento en que se produce.
El músculo ejecutor: Cloud Functions
El evento de Eventarc aterriza en una Cloud Function escrita en Python. Esta función tiene tres responsabilidades concretas:
Primero, extrae los campos relevantes del evento recibido — volumen de ventas, categoría de producto, histórico reciente — y aplica las transformaciones de preprocesamiento necesarias para que el modelo los entienda.
Segundo, construye el payload y llama al endpoint de inferencia de Vertex AI mediante una petición HTTP autenticada.
Tercero, recibe la predicción y decide qué hacer con ella. La función actúa como el director de orquesta que conecta la inteligencia del modelo con la operativa real del negocio.

Al ser serverless, esta función solo existe cuando hay trabajo que hacer. No hay servidor esperando. No hay coste en reposo.
El cerebro: Vertex AI

El modelo de forecasting vive en Vertex AI como un endpoint gestionado. Cuando recibe el payload de la Cloud Function, ejecuta la inferencia y devuelve la predicción en milisegundos.
Vertex AI no es solo un lugar donde hospedar el modelo — es el entorno que garantiza que ese modelo sea operable en producción. Gestiona el versionado automáticamente, lo que significa que cuando el equipo de datos entrene una versión mejorada del modelo, el endpoint se actualiza sin interrumpir el servicio. Monitoriza el rendimiento en tiempo real y alerta si la precisión del modelo empieza a degradarse — lo que en MLOps se conoce como data drift.
Este es el componente que transforma un experimento en un sistema resiliente.
Cerrando el bucle: de la predicción a la acción
Una predicción que no mueve nada es un informe caro.
La Cloud Function recibe el resultado de Vertex AI y, en función del umbral definido, dispara una notificación automática al equipo comercial vía email. Si el modelo detecta una caída significativa en la demanda prevista para los próximos 7 días, el responsable comercial recibe un aviso en su bandeja de entrada con el dato concreto antes de que el problema ocurra.
No hay un analista mirando un dashboard. No hay un Excel que alguien tiene que revisar el lunes. El sistema observa, predice y comunica — de forma autónoma y continua.
Este es el cierre del bucle que distingue una arquitectura MLOps real de un modelo que vive en un notebook.
Conclusión
Llevar un modelo de forecasting a producción no es un problema de algoritmos. Es un problema de arquitectura.
La precisión del modelo importa, pero lo que determina si una predicción genera valor real es lo que ocurre alrededor de ella: cómo llega el dato, quién orquesta el flujo, cómo se sirve la inferencia y, sobre todo, qué acción dispara el resultado.
El stack que hemos visto en este artículo — BigQuery, Eventarc, Vertex AI y Cloud Functions — no es la única forma de resolver este problema. Es una forma probada, serverless y orientada a escalar sin que el coste se dispare ni el equipo técnico tenga que crecer proporcionalmente.
La diferencia entre una empresa que toma decisiones comerciales con datos y una que sigue dependiendo del criterio de alguien que revisó un Excel el viernes, no está en tener el mejor modelo. Está en haber cerrado el bucle.
Si quieres ver esta arquitectura de forma visual antes de implementarla, he preparado un blueprint descargable con el diagrama completo del pipeline, los servicios involucrados y las decisiones de diseño clave.